https://www.youtube.com/watch?v=cdGBloT9vDk
1. import
re는 Python의 정규표현식(regular expression, 정규식) 처리 모듈입니다. 텍스트 안에서 특정한 패턴을 찾거나, 바꾸거나, 분리하는 데 쓰입니다.
import numpy as np
import re
2. 데이터
data = "나라의 말이 중국과 달라 문자와 서로 통하지 아니하기에 이런 까닭으로 어리석은 박성이 이르고자 할 바가 있어도 마침내 제 뜻을 능히 펴지 못할 사람이 많으니라 내가 이를 위"
3. tokenization
def data_preprocessing(data):
# 한글만 남기고 나머지는 제거
data = re.sub(r'[^가-힣\s]', '', data)
# 토큰화 (띄어쓰기 기준)
tokens = data.split()
# 고유 단어 집합
vocab = list(set(tokens))
vocab_size = len(vocab)
# 단어 → 인덱스
word_to_ix = {word: i for i, word in enumerate(vocab)}
#{'나라의': 0, '말이': 1, '중국과': 2}
# 인덱스 → 단어
ix_to_word = {i: word for i, word in enumerate(vocab)}
#{0: '나라의', 1: '말이', 2: '중국과'}
return tokens, vocab_size, word_to_ix, ix_to_word
# 실행 예시
tokens, vocab_size, word_to_ix, ix_to_word = data_preprocessing(data)
print("토큰:", tokens[:10])
print("어휘 수:", vocab_size)
print("word_to_ix 예시:", list(word_to_ix.items())[:5])
다음 코드에서는 간단하게 텍스트 전처리 파이프라인을 볼 수 있는데요.
원문 입력 -> 전처리 (Cleaning)-> 토큰화 (Tokenization) -> 어휘집(vocabulary) 생성 -> 단어 → 인덱스 매핑 -> 인덱스 → 단어 매핑 -> 최종 반환 이 순서로 이루어지고 있습니다.
tokenization(토큰화)는 여러 종류가 있지만 여기서는 단어를 띄어쓰기 단위로 나누는 간단한 처리만 해주었습니다.(split)
# 일반적으로 토큰화에서는 NLTK 라는 자연어 처리 파이썬 패키지를 사용하는 데 이 프로젝트는 간단하므로 NLTK를 사용하지는 않았습니다. NLTK는 토큰화(tokenization), 형태소 분리, 불용어 제거(stopwords), 어간 추출(stemming), 표제어 추출(lemmatization) 같은 다양한 텍스트 전처리를 제공합니다. https://wikidocs.net/22488
이후에는 token에서 중복되는 것을 제외(set)하고 그 리스트의 크기를 계산합니다.
딥러닝은 단어 자체를 바로 처리하지 못하기 때문에 이것을 숫자로 바꾸어주어야 합니다. 단어에 붙은 인덱스는 나중에 onehot encoding에 사용됩니다.(word_to_ix)
ix_to_word는 사람이 이해할 수 있는 언어로 변환한 것입니다. 서로 역방향 변환을 쉽게 하기 위해 두 개를 같이 만들었습니다.
4. 신경망 가중치 초기화함수
import numpy as np
def init_weights(h_size, vocab_size):
# U: 입력 → hidden
U = np.random.randn(h_size, vocab_size) * 0.01
# W: hidden → hidden (RNN의 recurrent connection)
W = np.random.randn(h_size, h_size) * 0.01
# V: hidden → 출력 (vocab 크기만큼)
V = np.random.randn(vocab_size, h_size) * 0.01
return U, W, V
u,v,w 벡터 3가지 가중치가 RNN에서 사용됩니다.
5.feedforward함수
RNN(Recurrent Neural Network) 은 문장을 단어 단위로 하나씩 읽습니다.
각 시점 t에서 입력 단어(input)를 받아서 hidden state(h_t)를 계산하고, 그걸 바탕으로 다음 단어를 예측합니다.
예를 들어 input가 "나라의" 라면 target으로 들어오는 것은 "말이"입니다.

RNN은 단순히 입력 단어만 보는 게 아니라, 이전까지 읽은 문맥도 함께 사용합니다.
그 문맥이 바로 hidden state (h_t).
hprev는 h_(t-1) → 즉, 바로 이전 시점의 hidden state를 의미합니다.
hs[-1] = np.copy(hprev) 이 부분에서 초기 hidden state로 받아들여서 순전파를 시작합니다.
def feedforward(inputs, targets, hprev):
#초기화
loss = 0
xs, hs, ps, ys = {}, {}, {}, {}
hs[-1] = np.copy(hprev)
#시퀀스 순회
for i in range(len(inputs)): # seq_len 대신 len(inputs) 사용
#입력을 one-hot으로 변환
xs[i] = np.zeros((vocab_size, 1))
xs[i][inputs[i]] = 1 # 각각의 word에 대한 one hot coding
#hidden state 계산 (RNN)
hs[i] = np.tanh(np.dot(U, xs[i]) + np.dot(W, hs[i-1]))
#출력 계산
ys[i] = np.dot(V, hs[i])
ps[i] = np.exp(ys[i]) / np.sum(np.exp(ys[i])) # softmax 계산
#loss 계산
loss += -np.log(ps[i][targets[i], 0])
return loss, ps, hs, xs
1) 초기화
- xs: 입력(one-hot) 저장
- hs: hidden state 저장, 이전 시점 hidden state hs[-1] 초기화
- ps: 출력 확률 저장
- ys: hidden → 출력 변환값 저장
- loss 초기화
2) 시퀀스 순회
시퀀스 길이만큼 반복하며 각 단어를 처리합니다.
3) 입력을 one-hot으로 변환
- vocab_size 크기의 벡터 생성 후, 현재 단어 위치를 1로 설정
- 예시: 단어 인덱스가 3이면 [0, 0, 0, 1, 0, ...]
4) hidden state 계산 (RNN)
RNN에서 hidden state는 단순히 선형 연산(U·x + W·h_prev)만 하면
→ 다음 hidden state가 무한히 커지거나 0으로 수렴할 수 있습니다. 따라서 비선형성(non-linearity)하게 만들기 위해 [-1,1] 범위인 tanh(x)를 선택하여 사용했습니다.(sigmoid나 ReLU에 비해 좋다)
5) 출력 계산
hidden → 출력: V * hs[i]
softmax를 적용하여 확률 벡터를 생성합니다. (ps[i])
ps[i][j] = 단어 j가 다음 단어일 확률
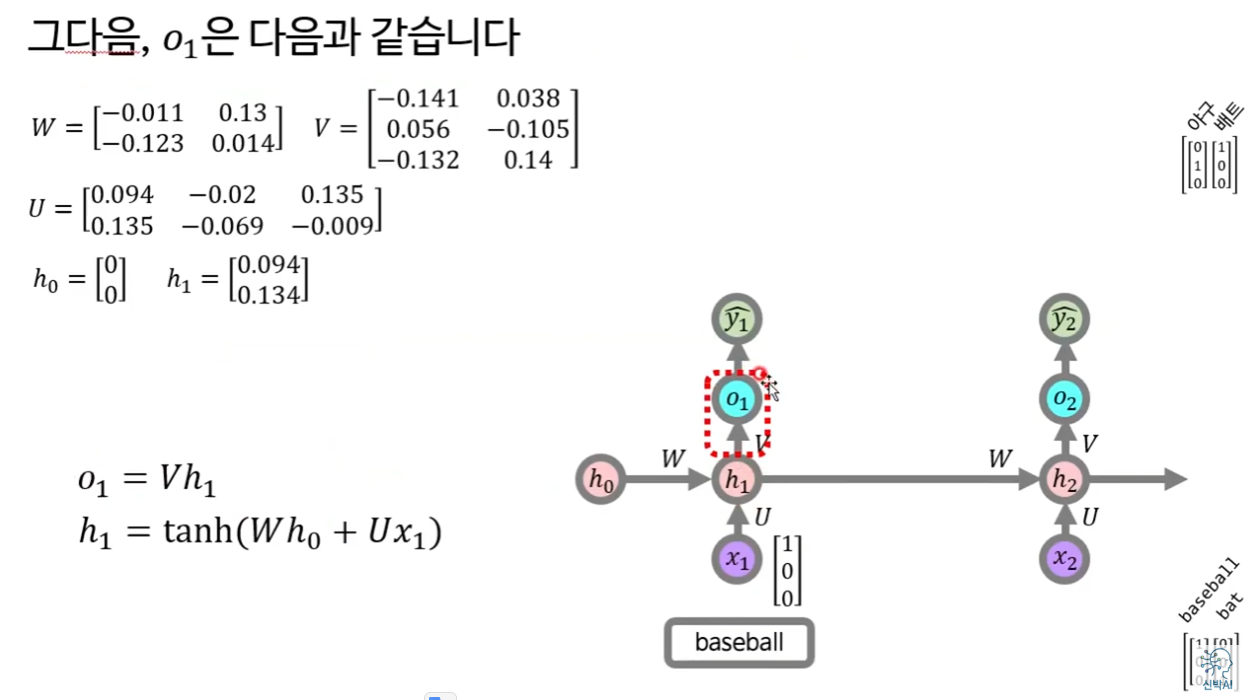
6) loss계산
- 크로스 엔트로피(cross-entropy) 손실
- 정답 단어 확률의 로그를 취하고 부호를 바꾼 후 누적
처음의 모든 가중치를 0으로 초기화하였습니다.
시간 순의 역순으로 가야 하기 때문에 [::-1]로 작성했습니다.
output의 onehot encoding이 정답이기 때문에
6. backward함수
def backward(ps, hs, xs):
# Backward propagation through time (BPTT)
# 처음에 모든 가중치들은 0으로 설정
dv = np.zeros(V.shape)
dw = np.zeros(W.shape)
du = np.zeros(U.shape)
for i in range(seq_len)[::-1]:
output = np.zeros((vocab_size, 1))
output[targets[i]] = 1
ps[i] = ps[i] - output.reshape(-1, 1)
# 매번 i스텝에서 dL/dVi를 구하기
dv_step_i = ps[i] @ (hs[i]).T # (y_hat - y) @ hs.T - for each step
dv = dv + dv_step_i # dL/dVi를 다 더하기
# 각 i별로 V와 W를 구하기 위해서는
# 먼저 공통적으로 계산되는 부분을 delta로 해서 계산해두고
# 그리고 시간을 거슬러 dL/dwij와 dL/duij를 구한 뒤
# 각각을 합하여 dL/dw와 dL/du를 구하고
# 다시 공통적으로 계산되는 delta를 업데이트
# i번째 스텝에서 공통적으로 사용될 delta
delta_recent = (V.T @ ps[i]) * (1 - hs[i] ** 2)
# 시간을 거슬러 올라가서 dL/dw와 dL/du를 구함
for j in range(i + 1)[::-1]:
dw_ij = delta_recent @ hs[j - 1].T
dw = dw + dw_ij
du_ij = delta_recent @ xs[j].reshape(1, -1)
du = du + du_ij
# 그리고 다음번 j-1번 타임에서 공통적으로 계산할 delta를 업데이트
delta_recent = (W.T @ delta_recent) * (1 - hs[j - 1] ** 2)
for d in [du, dw, dv]:
np.clip(d, -1, 1, out=d)
return du, dw, dv, hs[len(inputs) - 1]
7. predict함수
predict 함수는 주어진 단어를 시작으로 다음 단어들을 예측하여 문장을 생성하는 함수입니다.
def predict(word, length):
#입력 단어를 원-핫 벡터로 변환
x = np.zeros((vocab_size, 1))
x[word_to_ix[word]] = 1
ixes = []
#숨겨진 상태(h) 초기화
h = np.zeros((h_size, 1)) # 오타 수정: h 초기화
#다음 단어를 순차적으로 예측
for t in range(length):
h = np.tanh(np.dot(U, x) + np.dot(W, h)) # 오타 수정: '+' 누락, 변수명 W
y = np.dot(V, h)
p = np.exp(y) / np.sum(np.exp(y)) # 소프트맥스 계산
ix = np.argmax(p) # 가장 높은 확률의 index
x = np.zeros((vocab_size, 1))
x[ix] = 1 # 오타 수정: '-1' → '=1'
ixes.append(ix)
#예측된 단어들을 다시 문자열로 변환
pred_words = ' '.join(ix_to_word[i] for i in ixes)
return pred_words
8. parameters
# 학습 파라미터
epochs = 10000 # 학습 반복 횟수
h_size = 100 # hidden state 크기
seq_len = 3 # 시퀀스 길이
learning_rate = 1e-2 # 학습률
# 데이터 전처리
tokens, vocab_size, word_to_ix, ix_to_word = data_preprocessing(data)
9. 학습
# 가중치 초기화
U, W, V = init_weights(h_size, vocab_size)
hprev = np.zeros((h_size, 1))
for epoch in range(epochs):
for p in range(len(tokens) - seq_len):
# 입력과 타깃 시퀀스 준비
inputs = [word_to_ix[tok] for tok in tokens[p:p+seq_len]]
targets = [word_to_ix[tok] for tok in tokens[p+1:p+seq_len+1]]
# 순전파
loss, ps, hs, xs = feedforward(inputs, targets, hprev)
# 역전파
du, dw, dv, hprev = backward(ps, hs, xs)
# 가중치 업데이트
U -= learning_rate * du
W -= learning_rate * dw
V -= learning_rate * dv
# 학습 상태 출력
if epoch % 100 == 0:
print(f'epoch {epoch}, loss: {loss}')
이러한 원시적인 RNN모델은 다음에 올 단어를 확률적으로 계속 예측하는 모델입니다. gpt도 초기에는 이러한 형태였죠.
여기서는 훈민정음만 학습 시켰기 때문에 "나라의" 다음에 "말이" 가 나오게만 작동합니다.
RNN보다는 LSTM이 훨씬 예측이 뛰어납니다. 하지만 시계열 데이터 가장 원시적인 형태이기 때문에 이렇게 학습했습니다.

참고자료
https://wikidocs.net/21698
02-01 토큰화(Tokenization)
자연어 처리에서 크롤링 등으로 얻어낸 코퍼스 데이터가 필요에 맞게 전처리되지 않은 상태라면, 해당 데이터를 사용하고자하는 용도에 맞게 토큰화(tokenization) & 정제(c…
wikidocs.net
'대학강의정리 > 25.1 인공지능응용' 카테고리의 다른 글
| 서버시스템 구축 실습하면서 배운 것들(gcp) (0) | 2025.09.02 |
|---|---|
| gcp로 flask 서버 돌리기 - gpu 리소스 할당 받기 (0) | 2025.09.02 |
| 7주차. RNN (0) | 2025.04.24 |
| 6주차. CNN 실습 코드 (0) | 2025.04.17 |
| 6주차. CNN 개념 (0) | 2025.04.17 |