ML 소개
#YOLO 알고리즘
1. AI와 데이터
공학의 기본은 input을 통해 output을 내놓는 시스템(function)을 만드는 것입니다. 우리는 오랫동안 우리가 가진 지식을 기반으로 새로운 기술을 만들어 냈습니다. 하지만 활용해야 할 데이터가 많아지고 만들어야 할 시스템이 복잡해지면서 사람의 지식(domain knowlege)을 기반으로 한 Model-driven approach에서 모호한 경험(experiment knowledge:양자 역학 같은거)을 기반으로 한 Data-driven approach가 필요해졌습니다. AI도 이를 기반으로 한 기술입니다. AI에 의해 직접 세계를 관찰하고 분류하는 것만이 아니라 데이터를 통해 세계를 보는 것도 가능해졌습니다. AI는 데이터 그 자체라고 이야기 되기도 합니다.
2. AI의 장점
AI는 사람과 달리 선입견과 감정이 없기 때문에 식별, 의사 결정 과정에서 객관적이 판단이 가능합니다.
성별에 따른 인구 분포같은 것도 시간에 따라 빠르게 변화합니다. 따라서 오래된 모델로는 데이터를 분석할 수 없는경우가 발생합니다. 하지만 AI를 통해 우리는 alive data에 빠르게 대처할 수 있습니다.
3. 데이터의 차원 (Dimentionality of data)
Data는 정보와 가치 한 쌍의 집합입니다. Data : {(xi, yi)} (i=1)...N
이미지를 예로 들면 흑백이미지는 2차원 matrix로 표현할 수 있지만 컬러 이미지는 2차원 matrix를 R,G,B 3개 겹친 것으로 표현해야 합니다. 이 데이터를 가공하기 위해서는 또 선형 벡터로 표현해야 합니다.
결국, 이미지 -> matrix -> 선형 벡터 순으로 바꾸어야 합니다.
데이터를 사용할 때는 데이터를 다루는 법도 알아야 하지만 reliance(신뢰성), distribution(통계), automatc labelling 등 여러 가지를 고려해야 합니다. AI는 데이터 그 자체나 다름 없기 때문에 데이터를 어떻게 다루고 수치화하는 지에 따라 AI의 성능이 달라집니다.
3. 머신러닝(Machine learning)이란
machine learning은 특수한 AI를 말합니다.
AI 정의는 인간 지능을 모방하는 프로그램(programs that imitate intelligence)입니다. 인간의 지능은 명확하게 정의할 수 없어 AI는 모호한 정의로 ML을 포함합니다. AI에는 random forest,decision tree가 있습니다.
ML은 AI의 일종으로 특수한 문제를 경험을 통해 해결합니다.( a part of AI to solve a specific problem given training data.)
tom michell은 머신러닝을 ETP(Experience, Task, Performance mearsure)로 설명했는데요. 구체적인 task에 대한 경험(experience)를 반복할 수록 성능 (performance)이 향상되는 프로그램을 머신러닝 프로그램이라고 했습니다.
예를 들어, 드론이 날다가 정확한 위치에 안정적이게 주차하는 프로그램을 만든다면 드론이 정해진 초기 위치와 목표지점을 반복해서 나는 것을 E, 목적지에 안정적(stability)이게 멈취서는 것을 T, 드론 안에 탑재된 자기센서로 속도, 기울어진 각을 추적하는 것을 P(performance measure)로 볼 수 있습니다.
ML에는 deep learning, NN(Neural Network), SVM(Support Vector Machine), Fuzzy, Gaussian process, DQN 등이 있습니다.
4. 머신러닝의 종류
기계학습의 여러 알고리즘들은 supervised learning, unsupervised learning, reinforcement learning 세 가지로 나눌 수 있습니다. 요즘(24.03.28기준)에는 한번에 모두 사용되기도 합니다.
1) supervised learning 지도 학습
지도학습은 (x,y)의 데이터 쌍이 준비된 상태에서 학습합니다. 학습데이터 y값을 사람이 컴퓨터에게 하나하나 알려주는 학습 방법입니다.
regression(회귀), classification(분류) 문제로 나누어집니다.
regression 회귀 분석은 연속된 대상(continuous target)에 대해 분석하고 classification 분류는 불연속적인 대상(discrete)에 대해 분석합니다. regression의 예로는 실수로 된 데이터가 있고 classification은 데이터가 어느 종류에 속하는지 판단하는 문제에서 많이 사용되기 때문에 이미지에서 사물을 인식하는 문제 등에 사용됩니다.
2) unsupervised learning 비지도 학습
비지도식 학습 기법은 y값 없이 x 값 만으로 학습합니다. 비지도 학습은 학습 알고리즘에 결과물이라고 할 수 있는 출력을 미리 제공하지 않고 인공지능(AI)이 입력 세트에서 패턴과 상관관계를 찾아내야 하는 머신러닝 알고리즘입니다. 데이터 자체가 부족하거나 훈련 데이터를 수집하기에는 비용이 너무 높은 등의 이유로 출력에 대해 알 수 없거나 활용할 수 없을 때 주로 사용됩니다. 보통 high dimentional space에서 low dimentional space로 축소시키는 데 사용됩니다.
clustering, outlier detection, feature extraction이 있습니다. 특히 요즘에는 feature extraction을 한 결과로 지도학습을 시도하기 때문에 feature extraction이 매우 중요하게 여겨집니다.
clustering은 각 개체의 그룹 정보(정답)없이 유사한 특성을 가진 개체끼리 군집화하는 것입니다. outlier detection은 군집화한 객체들 사이에서 혼자 툭 튀어나온 이상치를 찾아내는 것입니다.feature extraction은 주어진 정보를 압축시켜 특징들만 추출하는 것을 말합니다. 실제 세상은 text,음성, 영상, 자연어 등의 high dimensional space로 이루어져 있기 때문에 여기서 특징들만 추출하는 feature extraction이 선행되어야 supervised learning에서 더 성능이 좋은 학습을 진행할 수 있습니다.
3) reinforcement learning 강화학습
강화 학습 기법은 (x,y)값을 여러 개 이용합니다. 강화학습은 데이처를 수시로, 실시간으로 학습합니다. 역동적인 환경에서 반복적인 시행착오 상호작용을 통해 작업 수행 방법을 학습하는 머신러닝 기법을 말합니다. 앞서 말했던 ETP의 드론 예제가 강화학습을 이용한 것입니다. 스스로 성장하는 강화학습은 아직까지 실제 일상 생활에서 직접적으로 사용되는 경우는 거의 없습니다.
강화학습이란 어떤 Enviroment을 탐색하는 Agent가 현재의 State을 인식하여 어떤 Action을 취하면 그 행동에 대한 Reward가 주어지게 되고, Reward를 최대화하는 Action(수행)을 찾는 Policy(제어기)를 찾는 학습방법 입니다. (x1,y1) ->action -> (x2,y2) -> action -> (x3,y3) 이런 식으로 표현할 수 있습니다. action을 통해 새로운 데이터를 얻습니다.
action이 너무 단조로우면 충분한 데이터를 얻을 수 없고 action이 너무 random하면 경향성이 있는 데이터가 나오기 어렵습니다.
4) 지도학습, 비지도 학습, 강화학습의 관계
요즘은 기계학습에서 지도학습, 비지도 학습, 강화학습을 같이 사용합니다.
이미지 인식(image recognition)에서는 PCA, ICA, LDA,Manifold learning, Auto-encoder등의 비지도 학습을 통해 데이터를 압축하여 지도학습에 사용합니다.
자율 주행 자동차(self-driving vehicle)에서는 위의 비지도 학습과 지도 학습을 강화학습합니다(융합되어 있음). 여기서 강화학습에는 Q-learning, DDPG, A3c,GPS등 이 사용됩니다. 비지도 학습과 지도학습은 강화학습을 하기 위해 필수적입니다. 비지도 학습과 지도학습을 통해 x,y 관계를 모델링하고 그 외의 것들을 action을 통해 강화학습합니다.
결과적으로 supervised learning과 unsupervised learning은 목적은 다르지만 프로젝트를 하기 위해서는 같이 병행되어야하고 이것이 되어야 강화학습도 할 수 있습니다.
5. 딥러닝의 변화(딥러닝과 지도학습)
Neural Network -> Deep Neural Network -> Deep Learning
Neural Network는 딥러닝의 시작이라고 할 수 있습니다. 일차원 함수를 통해 0,1 구분 최적 모델을 구성하다가 XOR문제를 해결하기 위해 여러개의 선의 교집합을 찾아내는 방법을 사용했습니다.
NN을 구성하기 위해 퍼셉트론이라는 개념이 사용되었습니다. 각각의 input값에 가중치(weight)을 곱하고 이것을 하나로 모아 활성화 함수(step function or activation function,시그모이드 함수를 많이 사용한다.)를 통해 0이나 1의 값으로 output을 만들 때, 가중치의 최적값을 찾아내는 이 과정을 NN의 학습이라고 합니다. 여기서 사용되는 활성화 함수에는 sigmoid, ReLU, soft ReLU 등이 있습니다. 어느 임계값을 기준으로 0(deactivation)과 1(activation)을 나눕니다.
DNN(Deep Neural Network)는 뉴런 하나를 여러 개 조합해서 만든 네트워크입니다. gpu를 사용한 간단한 사칙연산의 반복으로 구현할 수 있습니다. 퍼셉트론을 여러 개 쌓을 수록 학습이 어려워지는 문제가 있었는데 이 문제를 해결한 것이 back propagation(역전파 알고리즘)입니다.
DNN은 어떻게 설계하느냐에 따라 여러 개의 개체를 동시에 추론할 수 있습니다.

추가자료:
6. CNN과 RNN
CNN(Convolution Neural Network)은 matrix를 vector로 만드는 과정에서 특성이 사라지지 않도록 추출합니다.
CNN은 비지도 학습인 feature extraction과 지도학습인 classification, 두 단계로 나누어지고 CNN자체는 지도학습으로 분류됩니다. CNN과 DNN이 연달아 일어납니사.
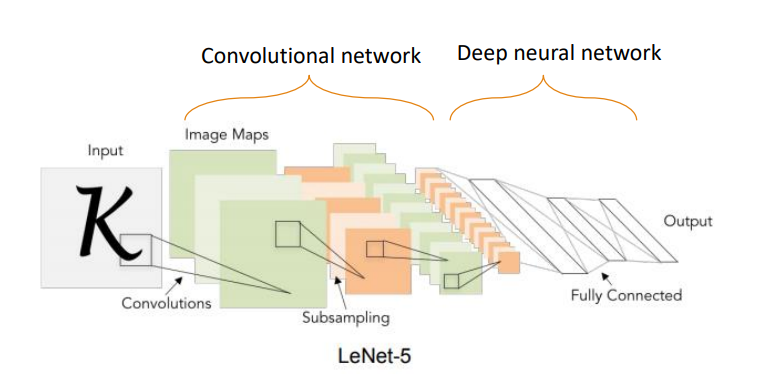
1) convolution layer-합성곱 계산
CNN에서는 이미지에 특정한 필터(kernel)을 적용해 이미지의 특징을 추출하고 원본이미지로부터 특징이 추출된 여러 이미지를 뽑아냅니다. image masking해서 image feature값을 계속 subsampling해갑니다.
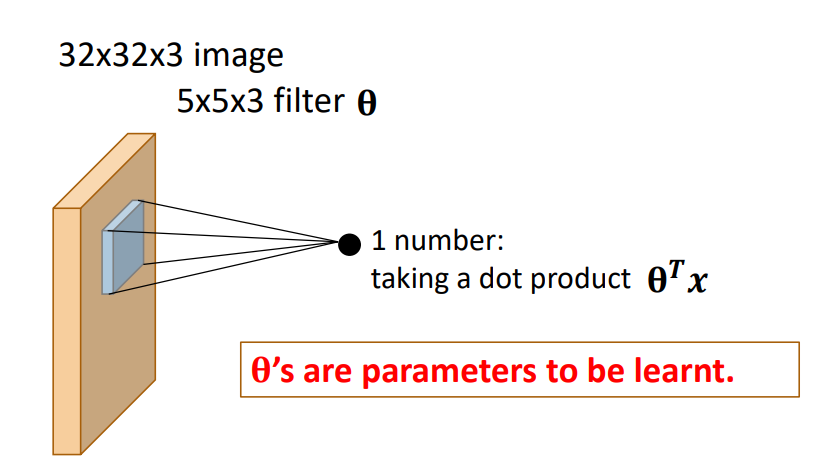
이미지 전체를 돋보기로 훑는다고 생각하면 편합니다.
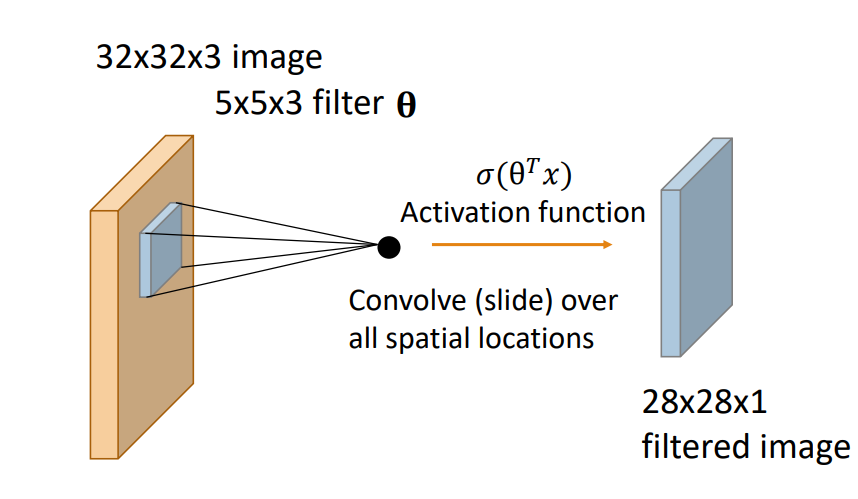
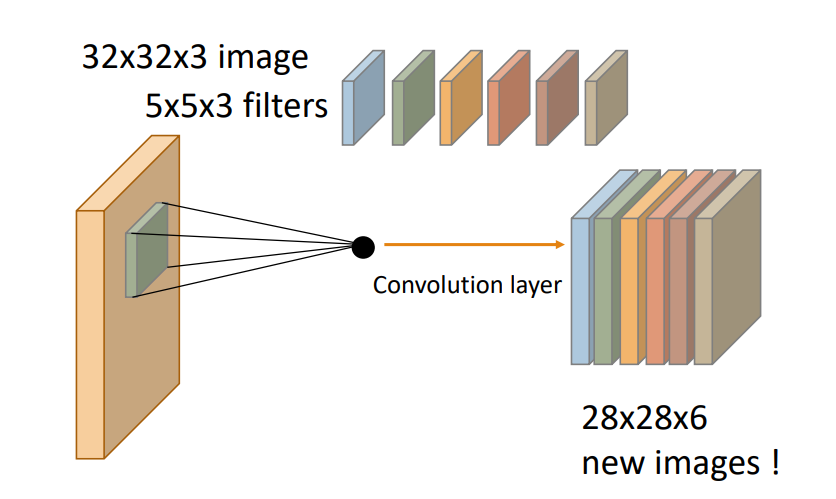
2) convolution layer-pooling
필터로 훑고 이미지 사이즈를 줄이는 단계입니다. 연산량을 줄이면서 feature의 특징을 강조할 수 있습니다. 해상도와 사이즈가 줄어듭니다. Max pooling과 average pooling으로 나누어집니다.
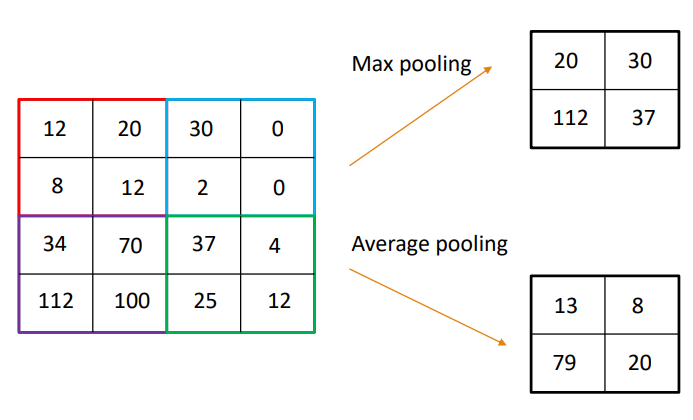
3) CNN은 합성곱과 pooling을 여러번 반복해 최적값을 찾아갑니다. 여기서 연산을 편하게 하기위해 역전파 알고리즘(back propagation)이 사용되었습니다. CNN은 구조를 마음대로 짤수 있다는 장점이 있습니다.
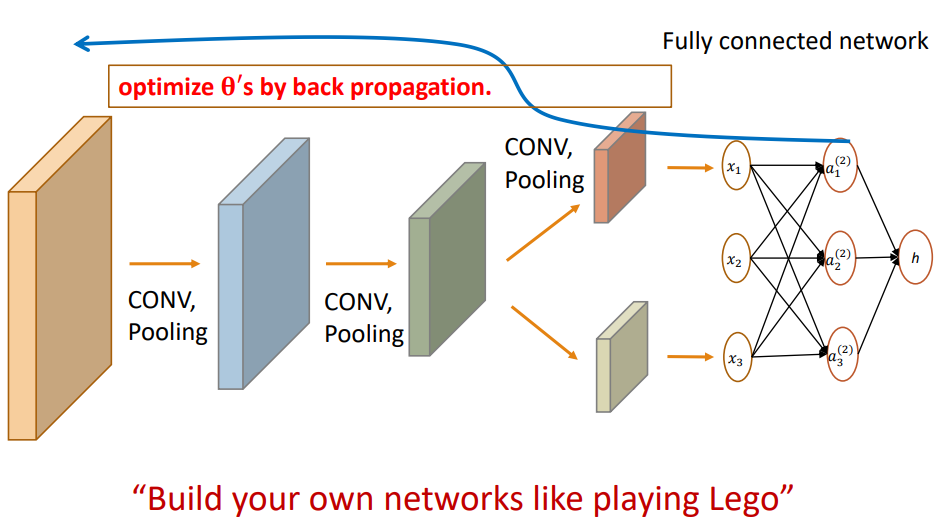
7. RNN(Recurrent Neural Network)
RNN은 앞의 DNN,CNN에 시계열 데이터(time-series date)를 추가한 것입니다. 시계열 데이터는 데이터의 순서가 시간순으로 정해져 있는 데이터입니다. 현재 데이터와 3초전 데이터는 다르게 취급합니다. Neural Network로 시간 순서대로 데이터를 처리합니다.
chatgpt도 RNN의 후속작이고 RNN은 딥러닝의 꽃이라고 볼 수 있습니다. 자연어를 처리할 수 있습니다.
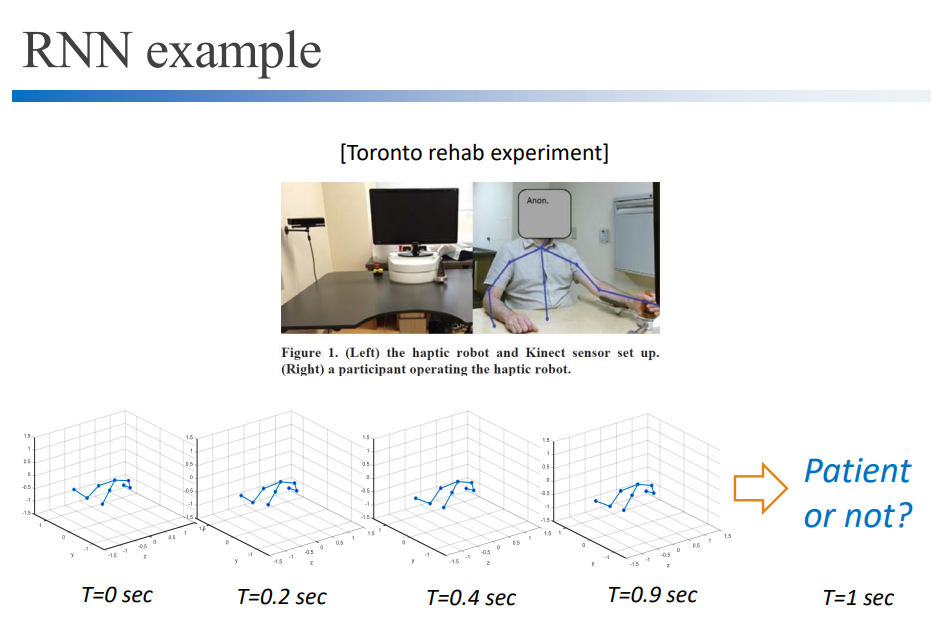
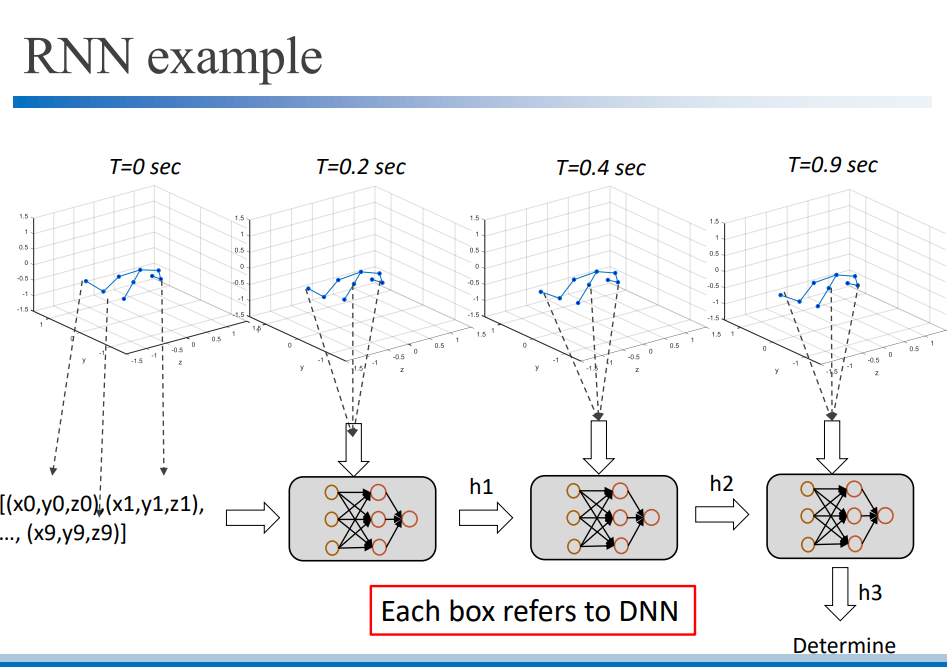
RNN은 안에 여러개의 DNN을 가지고 있습니다. 이 DNN은 일부 CNN으로 대체될 수 있습니다.
RNN은 시간에 따른 데이터이기 때문에 parameter가 많습니다. 학습시간은 RNN이 가장 오래걸리고 다음으로 CNN, DNN입니다.
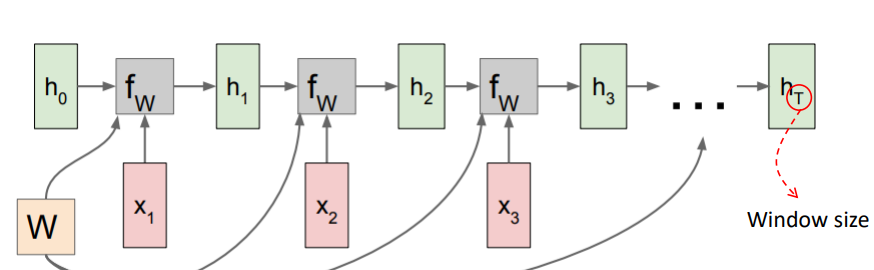
여기 쓰이는 DNN기술은 LSTM, GRU등이 있습니다.
머신러닝 메소드 자세한 설명
1. learning process(훈련 과정)
learning process는 반드시 training data와 test data를 분리해야 합니다.
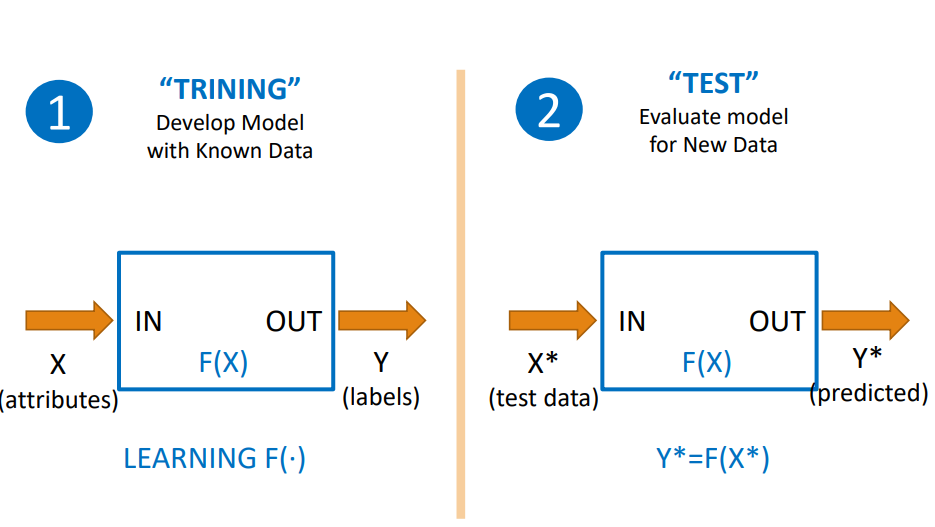
2. 지도학습 중 regression(회귀 분석)
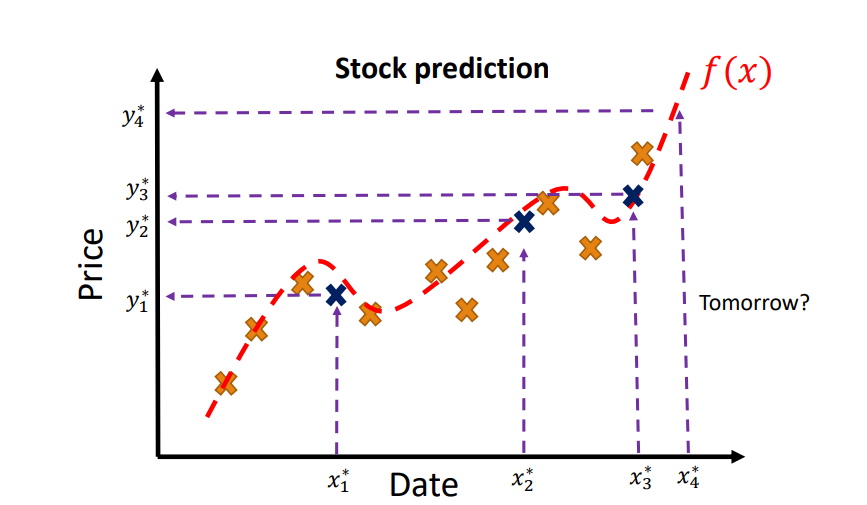
주어진 답(x, y)을 가지고 continuous valued output을 예측합니다.
3. 지도학습 중 Classification(분류)
0,1과 같은 discrete한 값으로 분류하는 classification입니다. 시그모이드 함수같은 활성화함수를 사용합니다. 학습할 때 함수의 기울기를 고려합니다.
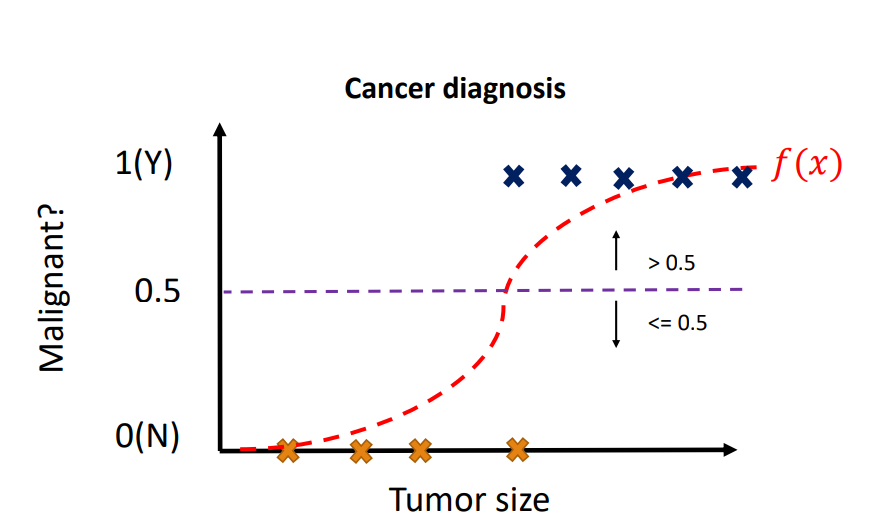
4. 비지도 학습- clustering and outlier detection(군집화와 이상치 찾기)
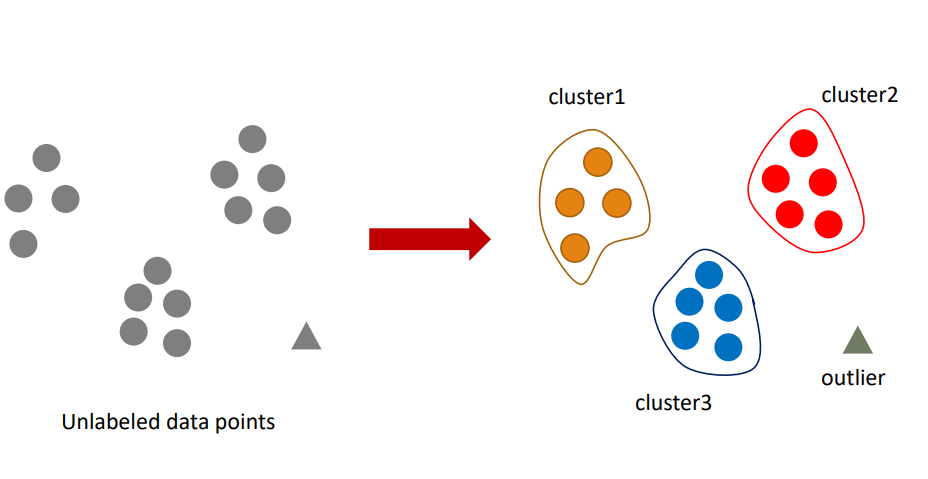
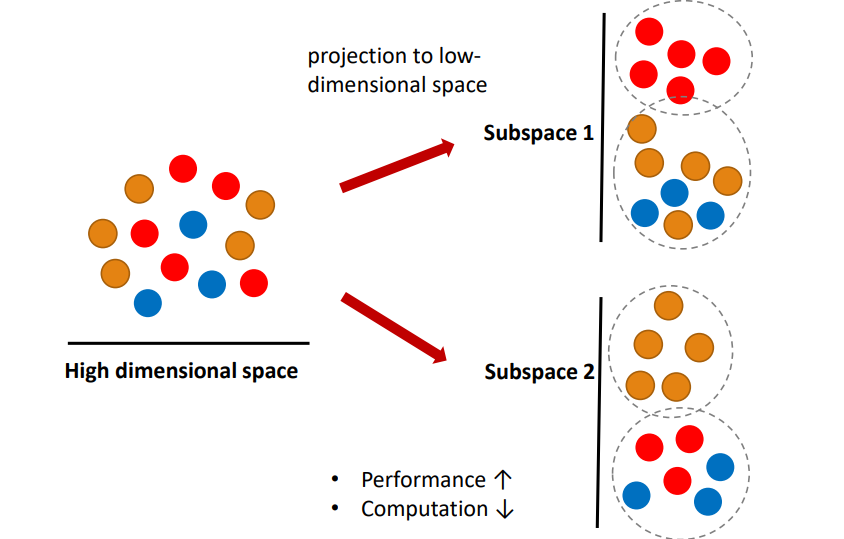
5. 비지도 학습- Dimensionality reduction차원다운 (or feature extraction 특징추출)
고차원 데이터를 저차원의 데이터로 projection하면 메모리 사용에 효과적이고 feature extraction이 되기 때문에 학습이 더 잘됩니다. 이를 기반으로 supervised leanging을 잘 할 수 있습니다.
6. reinforcement learning 강화학습
E(environment), T(task), P(performance)
주어진 환경에 따라 미래의 reward가 최고가 되는 최적의 action을 찾는 것이 목표인 학습입니다.
강화학습 vs 지도학습)
지도학습에 비해 환경이 고정되어 있지 않은 경우가 많기 때문에 일상생활에서 잘 활용할 수 없습니다. 하나하나 가르치는 supervised learning과 달리 안 가르쳐주고 스스로 합니다.

강화학습의 분류)
강화학습에는 model-based RL과 model-free RL이 있습니다.
state transition probability라고 현재상황(state)애서 어떤 action을 했을 때 다음 state를 예상하는 것을 Model-based는 하고 model free는 안 합니다. Q function만 있습니다.

model-bassed RL이 Model-free보다 빠릅니다. 대신 Model-free는 더 정확한 performance를 낼 수 있습니다.
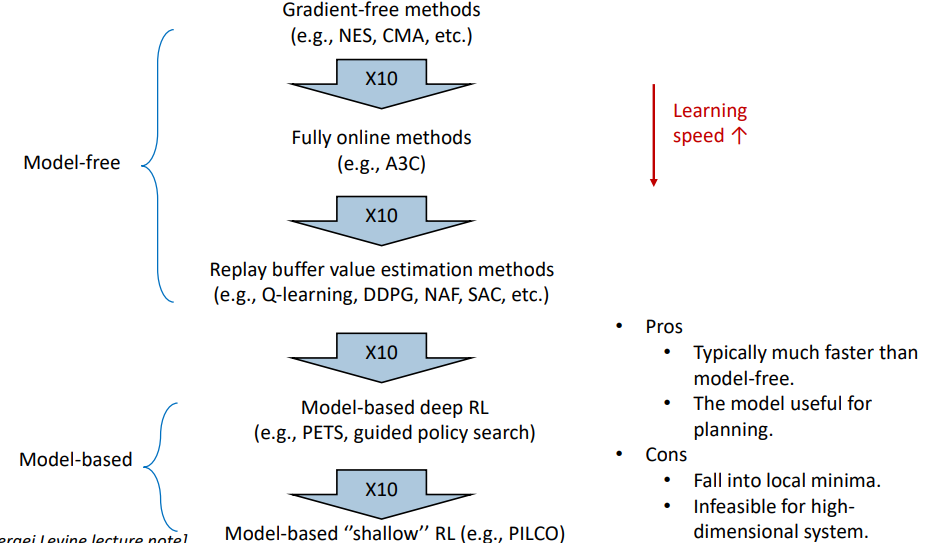
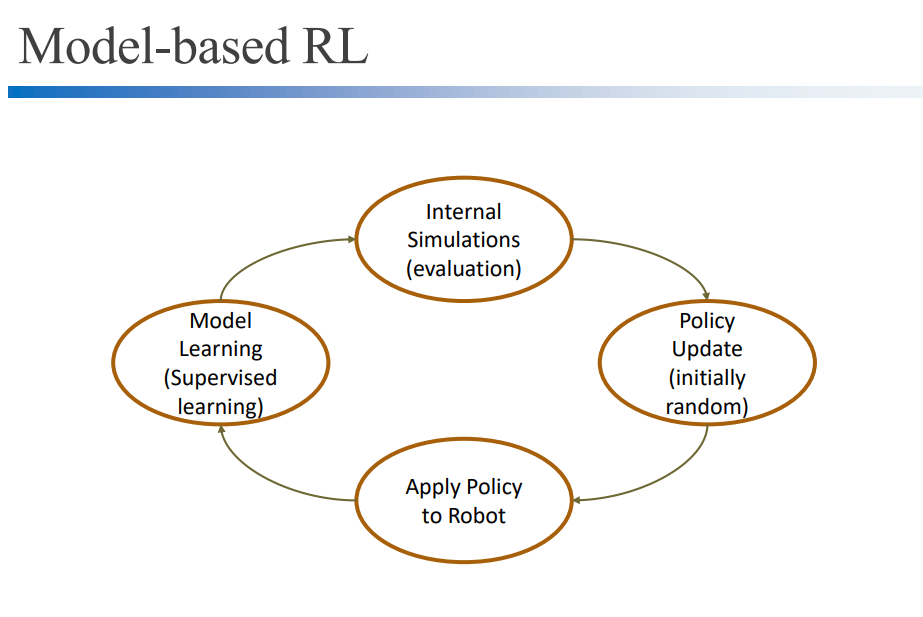
7. End to end deep learning
end to end deep learning 단계를 건너뛰고 바로 action 수행할 수 있게 바뀌었습니다. 여러 개의 구조를 매번 업데이트할 필요없이 하나의 네트워크가 강화학습을 할 수 있게 구현되었습니다. DNN 구조가 다 합쳐져 하나로 동작하기 시작했습니다.
'대학강의정리 > 기타' 카테고리의 다른 글
| 컴파일러.how c++ handle semantic errors (0) | 2025.02.03 |
|---|